
Heute mal ein kleiner Exkurs in die Welt des Betriebssystems. Wir haben vielleicht einmal den Bedarf, von einem bestimmten Einstiegspunkt rekursiv alle Dateien durch zugehen und dabei nur bestimmte Dateien zu bearbeiten. Das ist mit Python recht einfach. Als Besonderheit sei die Aufgabe gestellt, dass wir mit einer großen Anzahl an Dateien (Treffer oder nicht) rechnen müssen.
Grundsätzlich sehe ich zwei Möglichkeiten:
- Zunächst alle Verzeichnisse und Dateien durchgehen, die passenden ermitteln und diese mit ihrem kompletten Pfad in einer Liste sammeln. Die Liste wird dann im zweiten Schritt mit einem simplen “for datei in dateiliste” durchgegangen und die eigentliche Tätigkeit ausgeführt.
- Während des “Durchgehens” wird immer dann, wenn eine passende Datei gefunden wurde, sofort die entsprechende Aktion durchgeführt.
Sicher wird man zunächst die erste Lösung favorisieren. Die strenge Trennung von Suche und Ausführung hat ohne Zweifel einen gewissen Charme. Getreu dem Motto “separation of concerns” würden wir hierbei zwei auch unabhängig voneinander nutzbare Programmteile erhalten. Wenn es sich jedoch um sehr viele Dateien handelt, könnte es aus Benutzersicht etwas besser aussehen, wenn so früh wie möglich mit den Aktionen begonnen wird. Dass das in Python kein Widerspruch zu dem gewünschten Konzept ist, will ich an diesem Beispiel zeigen.
Die Kernfunktion
Zunächst wollen wir uns auf die Kernfunktion konzentrieren, das Durchgehen der Verzeichnisstruktur und das Sammeln der passenden Pfade in einer Liste. So eine Funktion kann man immer mal gebrauchen, sie sollte also so allgemeingültig wie möglich sein.
Zeile 4 definiert die Funktion, wobei ich das “pattern” mit ‘*.*’ vorbelegt habe. Wenn dieser Parameter nicht übergeben wird, ist das automatisch die Voreinstellung. Zeile 5 bis 10 sind der Docstring, der für die Dokumentation verwendet wird.
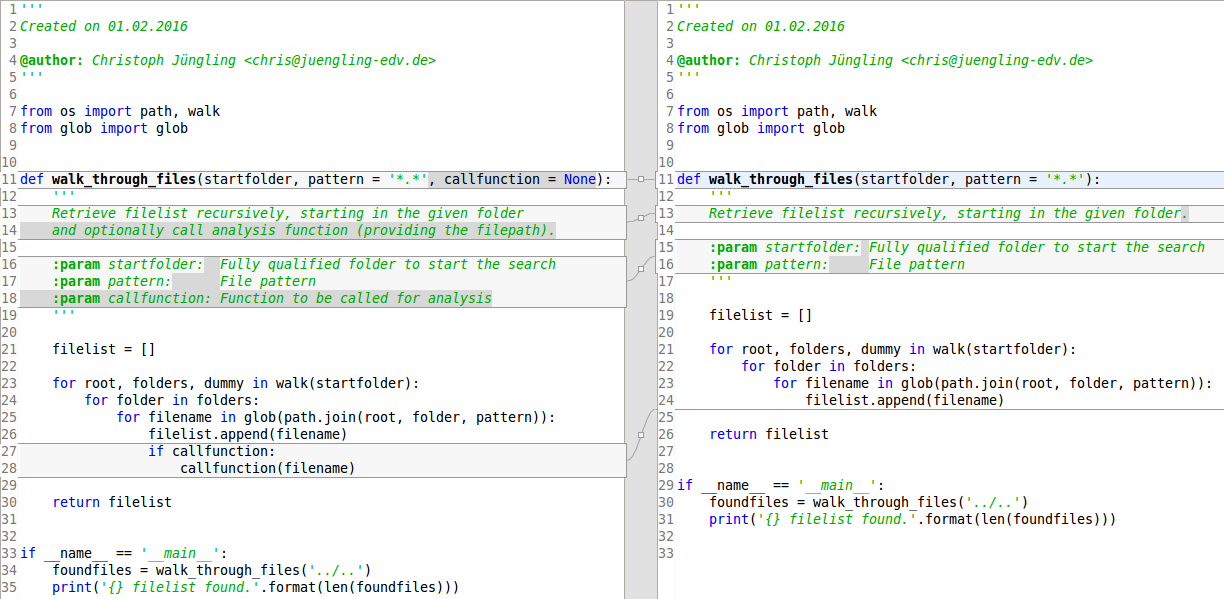
In Zeile 12 initialisieren wir die Variable als leere Liste. Zeile 14 wandert mit der Funktion “walk” aus dem Modul “os” alle Pfade rekursiv durch, nimmt uns also schon einen großen Teil der Arbeit ab. Dummerweise haben wir auf diese Weise keine Möglichkeit, das Suchmuster der Dateien zu überprüfen. Den dritten Wert (den in jedem Schleifendurchlauf gefundenen Dateinamen) lassen wir daher in der Variablen “dummy” versauern. Statt dessen kümmern wir uns nur um das jeweilige Basisverzeichnis (“root”) und die in diesem gefundenen weiteren Verzeichnisse (“folders”). Zeile 15 geht nun diese “folders” durch und bearbeitet jedes gefundene Verzeichnis einzeln. In Zeile 16 schließlich beschaffen wir uns mit der Funktion “glob” aus dem gleichnamigen Modul alle Dateien aus diesem Verzeichnis, die zu unserem Suchmuster passen. Diese wandern dann stückweise in Zeile 17 in unsere Liste “files”, die in Zeile 19 als Funktionsergebnis zurückgegeben wird.
from os import path, walk
from glob import glob
def walk_through_files(startfolder, pattern='*.*'):
'''
Retrieve files recursively, starting in the given folder.
:param startfolder: Fully qualified folder to start the search
:param pattern: File pattern
'''
files = []
for root, folders, dummy in walk(startfolder):
for folder in folders:
for filename in glob(path.join(root, folder, pattern)):
files.append(filename)
return files
Soweit, so gut, das funktioniert schon mal. Speichere den Code in einer Datei z.B. “durchmarsch.py” (Download), starte eine Python-Konsole und probiere es aus. Der erste Aufruf von “walk_through_files” liefert alle Dateien aus dem Windows-Verzeichnis als Liste zurück, der zweite nur die .exe-Dateien. Die Funktion “pprint” aus dem gleichnamigen Modul dient nur dazu, die evtl. sehr lange Liste etwas hübscher zu formatieren. Ein einfaches “print” hätte es natürlich auch getan.
from pprint import pprint
from durchmarsch import walk_through_files
pprint(walk_through_files('c:\\windows'))
pprint(walk_through_files('c:\\windows', '*.exe'))
Lasst Taten folgen
Das war die Pflicht, jetzt kommt dir Kür. Wie kriegen wir nun die Funktion zum Bearbeiten jeder gefundenen Datei in unsere fertige Funktion hinein, ohne das Konzept völlig umzukrempeln?
Sinnvollerweise benötigen wir dafür eine separate Funktion, die diese Aktionen durchführt. Diese Funktion benötigt nur den Pfad zu der Datei, alles andere macht sie selbst. Aus Gründen der Vereinfachung will ich mich hier auf eine kurze Textausgabe beschränken, damit das Prinzip klar wird. Auf Erklärungen kann ich wohl inzwischen verzichten :-)
def dateianalyse(filepath):
'''
Dummy-Funktion für eine hypothetische Dateianalyse
:param filepath: Pfad zur Datei
'''
print('Folgende Datei soll analysiert werden: {}'.format(filepath))
Selbstverständlich sind der Fantasie bei einer solchen Funktion keine Grenzen gesetzt. Der entscheidende Punkt ist dabei, dass es nur diese zusätzliche Funktion ist, die über diese Aktionen “Bescheid wissen” muss. Unsere Kernfunktion bleibt (fast) unverändert.
Eine kleine Änderung müssen wir aber doch machen, die ich mit Hilfe einer hilfreichen Funktion von Eclipse zeigen möchte. Eclipse speichert nämlich alte Stände unserer Datei eine gewisse Zeit lang. Das ermöglicht uns auch ohne Quellcodeverwaltung, den Weg unserer Arbeit zu verfolgen. Das ist über das Kontextmenü “Compare With -> Local History” des Editorfensters möglich. Die Einstellungen dazu finden sich in “Window -> Preferences -> General -> Workspace -> Local History”. Das Vergleichsfenster spricht sicher für sich selbst:

1 Kommentar
Gerade entdecke ich, dass es sogar noch einfacher geht. Zeile 15 aus obigem Listing kann nämlich entfallen, und damit natürlich auch die Variable “folder” in Zeile 16 :-)