
Ihr könnt euch denken, dass ich die Beiträge und den Code für das Projekt “Kaffeemaschine” nicht spontan jeden Freitag um 7 Uhr schreibe, um sie dann um 8 Uhr zu veröffentlichen. WordPress hat dankenswerterweise die Fähigkeit, Artikel vorab zu erstellen, nochmal zu überarbeiten, reviewen zu lassen, ein weiteres mal zu überarbeiten, usw., bis sie dann endlich fertig sind. Dann lässt sich der Artikel zu einem beliebigen Zeitpunkt in der Zukunft zur Veröffentlichung einplanen. Es gibt folglich immer einen gewissen Vorlauf.
Doch was WordPress kann, ist bei Bitbucket prinzipbedingt nicht vorgesehen. Den Code, den ich gerade eben hochgeladen habe, kann ab sofort jeder sehen. Wie behalte ich also den Überblick über den Code, der für die schon vorbereiteten, aber noch nicht veröffentlichten Artikel vorgesehen ist? Und wie arbeite ich weiter, ohne alles durcheinander zu bringen?
Quellcode-Verwaltung
Das Geheimnis heißt — natürlich — Mercurial, oder allgemein Quellcodeverwaltung. Dazu müssen wir uns von dem üblichen Modell, die Quellcodeverwaltung verwalte die vergangenen Commits, ein wenig verabschieden, denn dieses Bild ist nicht ganz vollständig.
Wie sicher bekannt ist, kann ich jederzeit zu einem früheren Stand zurückspringen, um z.B. einen Bug in einer bereits veröffentlichten Version zu untersuchen. In diesem Moment existieren sowohl die Vergangenheit als auch die Zukunft, denn die oberhalb des ausgecheckten Standes existierenden Commits sind aus der Sicht des Arbeitsverzeichnisses noch gar nicht vorhanden.
Des weiteren entscheide ich bei einer dezentralen Quellcodeverwaltung bewusst, welche Commits ich veröffentliche, und wann ich das tue. Dieser Vorgang wird bei Mercurial “push” genannt.
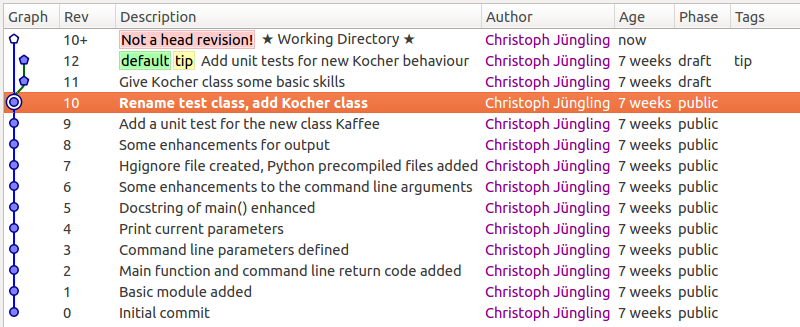
Das Bild verdeutlicht die Situation, wie sie gerade jetzt besteht. Das Changeset Nr. 10 ist das, was aktuell in meinem Arbeitsverzeichnis (Hg: “working directory”) existiert. Wie deutlich zu sehen ist, gibt es bei mir lokal noch zwei weitere, die aber noch in der Phase “draft” stehen. Das bedeutet, sie sind noch nicht veröffentlicht worden (wohin auch immer). Schauen wir uns die Commits auf Bitbucket an, dann sehen wir das passende Bild zum Zeitpunkt der Veröffentlichung dieses Artikels:
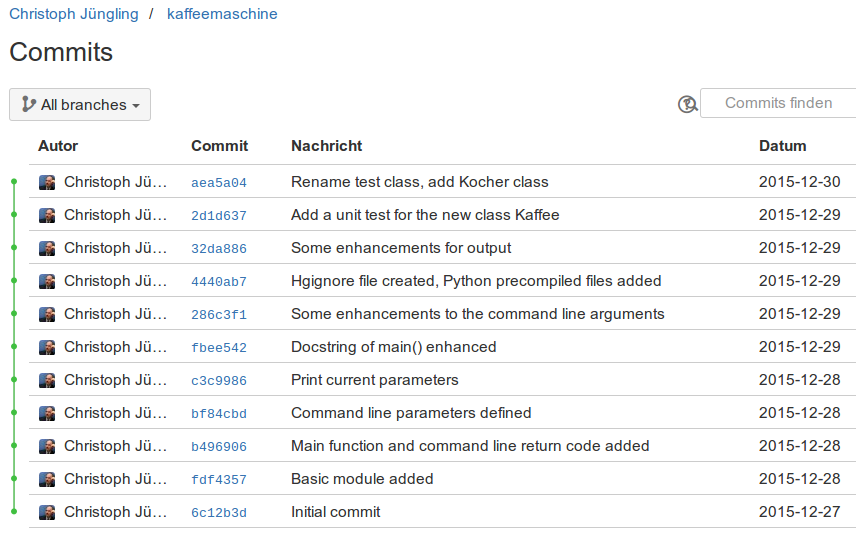 Dass die Nummern nicht übereinstimmen, liegt an der Art der Darstellung. TortoiseHg verwendet neben den Hashwerten üblicherweise die fortlaufende Nummerierung, um die Liste etwas übersichtlicher zu gestalten. Man muss sich nur darüber im Klaren sein, dass diese Nummerierung ausschließlich für das aktuelle Repository gilt, da hierin die Reihenfolge des Hinzufügens der Changesets abgebildet ist. Da Bitbucket der Kommunikation mit vielen Entwicklern dient, macht diese Darstellung dort keinen Sinn.
Dass die Nummern nicht übereinstimmen, liegt an der Art der Darstellung. TortoiseHg verwendet neben den Hashwerten üblicherweise die fortlaufende Nummerierung, um die Liste etwas übersichtlicher zu gestalten. Man muss sich nur darüber im Klaren sein, dass diese Nummerierung ausschließlich für das aktuelle Repository gilt, da hierin die Reihenfolge des Hinzufügens der Changesets abgebildet ist. Da Bitbucket der Kommunikation mit vielen Entwicklern dient, macht diese Darstellung dort keinen Sinn.
Ich verwende übrigens trotz der guten Integration von Mercurial in Eclipse lieber TortoiseHg, da dies den gesamten Sachverhalt noch viel besser darstellt. Eclipse kommt problemlos damit klar, wenn Dateien außerhalb des Editors verändert wurden (was bei dem Auschecken oder Patchen zwangsläufig geschieht) und bietet an, die Dateien nachzuladen. TortoiseHg läuft übrigens unter Windows und Linux, da es selbst — wie Mercurial — ebenfalls in Python geschrieben ist (mit Qt für die grafische Oberfläche). Wenn es noch eines Beweises für die Leistungsfähigkeit dieses Systems bedurft hätte, hier ist er.
Die Lösung
Und damit sind wir auch schon bei der Lösung des anfänglich geschilderten Problems. Wie man sieht, hatte ich die Programmierung in meinem lokalen Repository bereits vor Beginn der PyDay-Reihe in einem weiten Bereich vorbereitet, aber noch nicht vollständig hochgeladen. Das einzige, woran ich denken muss, ist, dass ich zeitnah zu jeder automatischen Veröffentlichung auch die passenden Changesets “pushe”.
Und ich sehe auch, dass es langsam mal Zeit wird, die Entwicklung der Kaffeemaschine voranzutreiben, denn die Zukunft ist nur noch zwei Changesets von der Gegenwart entfernt :-) Hat jemand noch ein paar Chronotonen übrig?

Neueste Kommentare