
Letzte Änderung am 28. Dezember 2021 by Christoph Jüngling
Über das Thema “Git vs. Subversion” wurde sicher schon viel geschrieben, und vermutlich wurden auch schon heftige Kämpfe ausgefochten. Daher kann ich mich bestenfalls aus meiner rein subjektiven Sicht dazu äußern. Es gibt jedoch einen Unterschied, der wohl zweifelsfrei als Vorteil gewertet werden kann. Dieser betrifft zwar nicht Git allein, sondern gilt für alle “verteilten” Quellcodeverwaltungen. Ich schildere es nur am Beispiel von Git.
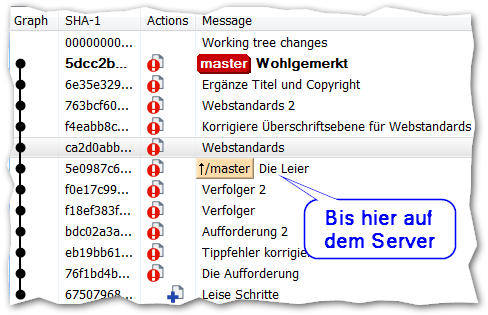
Git-Log (Beispiel): Nur ein Teil der Commits befindet sich bereits auf dem Server, der Rest kann von mir lokal noch verändert werden.
Zwei Tage Entwicklungsaufwand mit ständigem Hin und Her, bis dann endlich mal eine funktionierende und codemäßig gut lesbare Lösung herausgekommen ist! Da ist man schon froh, wenn die Arbeit endlich getan ist. Aber was ist mit der Quellcodeverwaltung? Refactoring, Korrektur, noch ein Refactoring, nebenbei noch ein Bug gefixt, der mit dem aktuellen Thema gar nichts zu tun hat … die gefühlt 100 Commits hätten in Subversion systembedingt jeweils sofort auf dem Server landen müssen. Lesbarkeit sieht sicher anders aus.
In Git hingegen ist die tatsächliche Zahl der Commits zunächst bedeutungslos, denn sie erfolgen nur lokal auf meinem Rechner und werden auch erstmal nur dort gelagert. Der zentrale Server (ja, sowas kann es auch bei Git geben) merkt davon nichts, und folglich auch die Kollegen nicht. Erst das Ergebnis wird “gepusht”, aber vorher kann ich noch mittels “Rebase” die Historie in eine lesbare Form bringen, z.B.:
- Refactoring-Schritte von “echten” Änderungen trennen
- Änderungen mit der Ticket-Nummer verknüpfen (die zu Beginn der Arbeiten vielleicht noch gar nicht existiert hat)
- Tests zusammen mit den Änderungen committen (oder wenigstens in zwei Commits nacheinander)
- Bei größeren Änderungen diese in sinnvolle Abschnitte unterteilen
Besonders der letzte Punkt wird gern diskutiert. Zu große Commits stehen im Gegensatz zu dem Wunsch nach möglichst übersichtlichen Commits, das ist immer eine ganz individuelle Abwägung. Doch wie auch immer, ich habe mit Git zumindest die Chance, mein Entwicklungstagebuch lesbar zu gestalten, was mir eine spätere Fehlersuche massiv erleichtert. Und Fehler passieren ja immer mal …
Während der Programmierung ist es daher völlig ausreichend, wenn ich meine Änderungen kleinschrittig committe und entsprechend kurze und knappe Commit Messages schreibe. Solange ich nicht gepusht habe, kann ich alles (!) nochmal ändern, zum Beispiel die Reihenfolge der Commits, das Zusammenfassen mehrerer Commits zu einem und den Beschreibungstext lesbar und nützlich abfassen. So liegt später auf dem Server eine sinnvolle Abfolge von stimmigen Änderungen, sauber kommentiert und mit dem Bugtracking-System verlinkt. Und nicht nur die Kollegen, sondern auch ich verstehe später noch, was ich da gemacht habe, warum und wie.

2 Kommentare
Spannende Informationen. Danke dafür.
GIT und SVN sind weit verbreitet unter Programmierern. Ich wuerde behaupten, dass GIT noch mehr Anhänger hat und es derzeit hauptsächlich verwendet wird. In Asien habe ich dagegen schon öfter Subversion gesehen.
Was nutzt Du bevorzugt?
Autor
Danke, freut mich, dass es dir gefällt :-)
Im Laufe der Zeit hat sich meine Gewohnheit deutlich verändert, von Visual Source Safe über SVN und Mercurial bis hin zu Git. Heute nutze ich nur noch Git, was sogar mit Microsofts Team Foundation Zeugs gut arbeiten kann (https://www.juengling-edv.de/git-und-die-team-foundation/).