
Letzte Änderung am 28. Dezember 2021 by Christoph Jüngling
![]()
![]() Wer beginnt, sich mit Git zu beschäftigen, steht sicher oft vor der Frage, wie man zu arbeiten hat. Die Frage ist nicht ganz einfach zu beantworten, denn Git selbst ist das ziemlich egal. Gut, es gibt Branches und Tags, das war es schon. Nicht einmal der Name des Haupt-Branches ist streng festgelegt. Und Server kann man beliebig viele einbinden. Das ist das Gute daran. Das ist das Schlechte daran.
Wer beginnt, sich mit Git zu beschäftigen, steht sicher oft vor der Frage, wie man zu arbeiten hat. Die Frage ist nicht ganz einfach zu beantworten, denn Git selbst ist das ziemlich egal. Gut, es gibt Branches und Tags, das war es schon. Nicht einmal der Name des Haupt-Branches ist streng festgelegt. Und Server kann man beliebig viele einbinden. Das ist das Gute daran. Das ist das Schlechte daran.
Vor kurzem unterhielt ich mich mit einem Kollegen über dieses Thema. Wir waren uns einig, dass an Git heute eigentlich kein Entwickler mehr vorbei kommt. Und die meisten würden sicher auch nicht mehr darauf verzichten wollen, wie auch immer das konkrete Quellcodeverwaltungssystem nun heißt. Doch wie genau arbeitet man denn nun mit Git?
Als ich mit Subversion (SVN) anfing, gab es ziemlich klare Regeln. Diese wurden zwar auch nur als “Empfehlung” bezeichnet, aber vermutlich haben sich fast alle daran gehalten:
- Der trunk stellt den Hauptentwicklungszweig dar.
- Ein branch enthält einen Entwicklungszweig (z.B. ein neues Feature oder einen Bugfix).
- Ein tag markiert eine bestimmte Stelle in der Entwicklung (z.B. die Versionsnummer eines Releases).
Branches und tags gibt es bei Git auch (und sie haben auch die gleiche Bedeutung), und der trunk heißt master (zu aktuellen Änderungen siehe diesen Artikel). Gar nicht so verschieden. Alles gut? Nun ja, im Grunde sind sich beide schon recht ähnlich, aber im Detail dann doch wieder unterschiedlich. Denn Subversion ist eine zentralisierte, Git eine verteilte Quellcodeverwaltung.
Zentralisiert bedeutet, dass man jeden Checkin sofort auf den Server schiebt. Dadurch bekommen andere Teammitglieder auch jeden Zwischenstand zur Verfügung gestellt. Aber was, wenn es eben wirklich nur ein Zwischenstand ist, der gar nicht compiliert, weil noch etwas fehlt? Wie sieht das dann mit einem automatischen Buildsystem aus, wenn jeder zweite Build crasht?
Bei Git ist das anders, oder besser, es kann anders sein. Denn bei einer verteilten Quellcodeverwaltung kann ich, so lange ich will, lokal arbeiten (auch auf Branches), ohne dass der zentrale Server etwas von meinen Commits (das, was bei Subversion Checkin heißt) mitbekommt. Es muss nicht einmal einen zentralen Server geben! Das heißt, wenn ich allein arbeite, geht das auch mit nur einem Computer :-) Erst wenn ich entscheide, dass meine Entwicklung weit genug ist, dass ich sie anderen zeigen kann, pushe ich diese auf den Server.
Da es bei Git sehr leicht ist, einen Branch zu erzeugen und zu löschen (letzteres erlaubt Subversion nicht!), kann und sollte man diese sehr oft verwenden. Einen guten Einstieg in verschiedene Branching-Modelle liefert dieser Artikel. Dabei ist wichtig, dass nicht jeder Branch unbedingt auf dem Server landen muss. Wenn ich z.B. einen Bug beheben muss, lege ich in der Regel einen lokalen Branch mit dem Namen “bugfix/1234” an, wobei 1234 hier für die Bugnummer steht. So kann ich die laufende Entwicklung schnell dem Bugreport zuordnen, denn davon kann es auch mehrere geben – gleichzeitig.
Wenn ich fertig bin und meine Tests erfolgreich absolviert habe, merge oder rebase ich diesen Branch in den master-Branch und lösche ihn wieder. Der Code bleibt erhalten, der Branch wird nicht mehr benötigt. Der master-Branch ist dabei langfristig der einzige, der dauerhaft existiert. Dieser wird natürlich zeitnah gepusht, und aus diesem wird per Continuous Integration auch der Build erzeugt.
Bei einem neuen Feature gehe ich genauso vor, nur dass der Branch dann “feature/1234” heißt.
Da man leider nur allzu oft bei der Arbeit unterbrochen wird, ist die Arbeit auf einem Branch in Git sehr hilfreich, um den Überblick nicht zu verlieren. Mit den genannten Präfixen zu den Branchnamen (man kann sich diese Nomenklatur auch als Analogie zu Verzeichnissen vorstellen) lassen sich auch in TortoiseGit recht schnell die noch offenen Arbeiten identifizieren, da diese hier hierarchisch dargestellt werden:
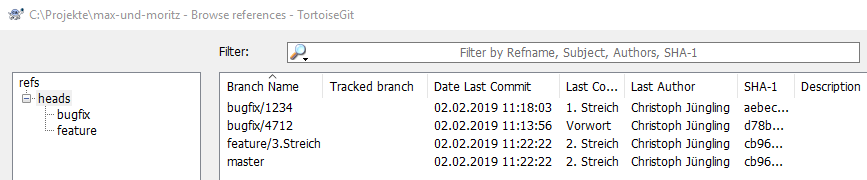
Und allen, die befürchten sie könnten Code verlieren, wenn die Festplatte während der lokalen Arbeiten eines spontanen Todes stirbt, möchte ich diese Frage mit auf den Weg geben: Wie oft ist euch das in den letzten drei Jahrzehnten passiert? Und wie oft konntet ihr nicht arbeiten, weil das Netzwerk ein Problem hatte?
Und wenn von mir verlangt wird, meinen Code auf Subversion abzulegen? Kein Problem, Git kann sehr gut mit einem Subversion-Server umgehen, und mit ein wenig Trickserei auch mit Microsofts Team Foundation. Dann hat man beides: Lokale Flexibilität, und der Chef ist ebenfalls zufrieden. Ich jedenfalls möchte Git nicht mehr missen!
Update: “Rebase” als Alternative zum “Merge” erwähnt.
Update 2: Neuen Artikel über den Default-Branch ergänzt.
Update 3: Link zum Team-Foundation-Artikel hinzugefügt.

Neueste Kommentare